لینک کوتاه : https://magicfile.ir/?p=2453
دانلود سورس کد تشخیص زبان یک متن نوشته شده با vb.net
سورس کد تشخیص زبان یک متن نوشته شده با vb.net برای شما کاربران عزیز وبسایت فایل سحرآمیز آماده دانلود قرار داده ایم. تشخیص زبان راه حل داده شده بر اساس n-gram و مقایسه وقوع کلمه است. برای هر زبانی که از کلمات استفاده می کند مناسب است (این در واقع برای همه زبان ها صادق نیست). بسته به مدل و طول متن ورودی، دقت بین 70% (فقط کوتاه نروژی، سوئدیش و دانیش که توسط مدل "همه" طبقه بندی شده اند) و 99.8٪ با استفاده از مدل "پیش فرض" است.
زمینه
تشخیص زبان یک متن نوشته شده احتمالاً یکی از اساسی ترین وظایف در پردازش زبان طبیعی (NLP) است. برای هر زبانی که بسته به پردازش یک متن ناشناخته، اولین چیزی که باید بدانید این است که متن به چه زبانی نوشته شده است. خوشبختانه، این یکی از چالشهای سادهتر NLP است. رویکردی که من برای پیاده سازی انتخاب کرده ام به طور گسترده شناخته شده و بسیار ساده است. ایده این است که هر زبان دارای یک مجموعه منحصر به فرد از کاراکترهای (هم) وقوع است.
نمونه از تصاویر در زمان اجرا
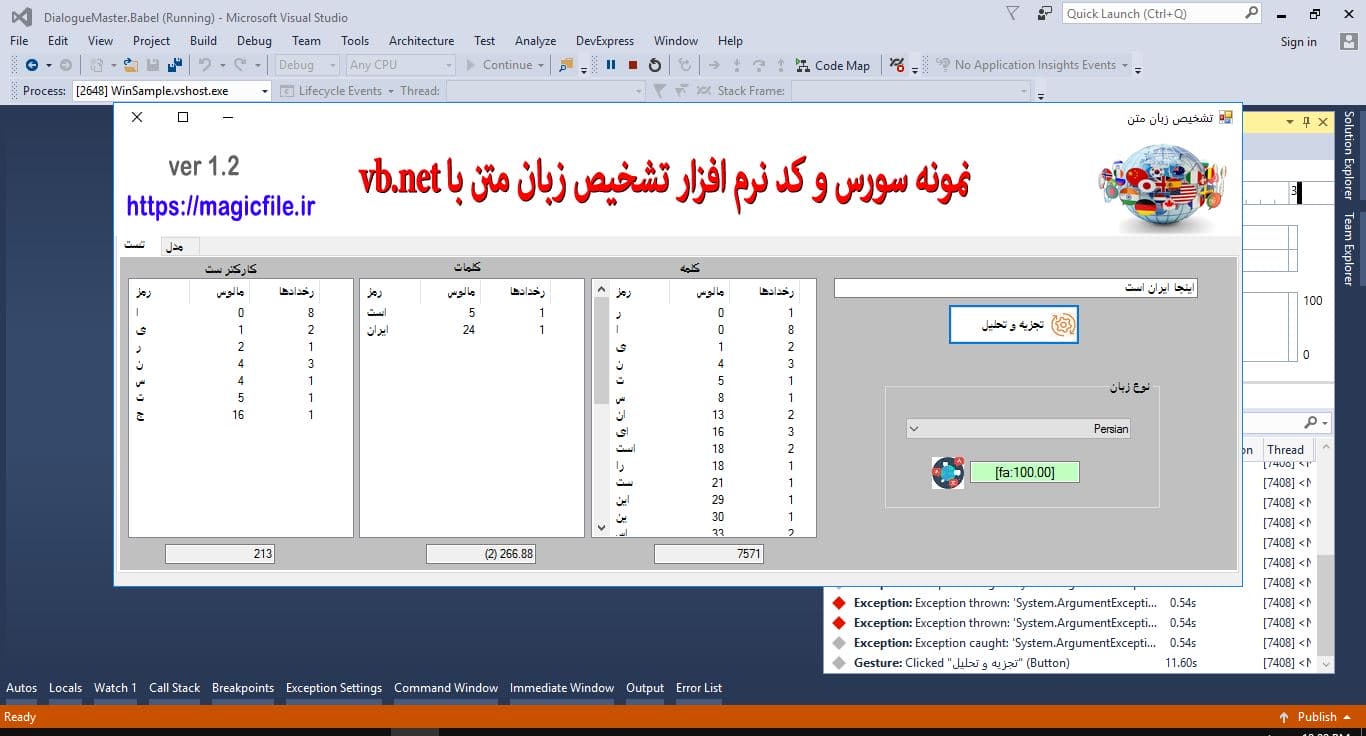
اولین قدم جمع آوری آن آمار برای همه زبان هایی است که باید قابل تشخیص باشند. این به آن راحتی که ممکن است در وهله اول به نظر برسد نیست. مشکل جمع آوری مجموعه بزرگی از داده های آزمایشی (متن ساده) است که فقط یک زبان را شامل می شود و مختص دامنه نیست. (فقط مقالات روزنامه ها ممکن است فاقد استفاده از کلمه "I" و گفتار مستقیم باشند. استفاده از نمایشنامه های شکسپیر بهترین رویکرد برای تشخیص متون معاصر نخواهد بود. مقالات پزشکی معمولاً حاوی بسیاری از اصطلاحات خاص دامنه هستند که حتی مختص زبان نیستند (عمده ، مینور، شریان و غیره...) و اگر این کار به اندازه کافی سخت نیست، متون نباید دارای حق چاپ باشند. (من مطمئن نیستم که آیا این یک الزام واقعی است. آیا نتایج تجزیه و تحلیل آماری متون دارای حق چاپ نیز دارای حق چاپ است؟) من انتخاب کردم که از ویکی پدیا به عنوان منبع اصلی خود استفاده کنم. مجبور شدم مقداری فیلتر کنم تا " ویکیپدیا حاوی نامهای مناسب زیادی است (یعنی نام گروهها) که اغلب حاوی یک «the» یا «and» هستند. به همین دلیل است که آن کلمات در بسیاری از زبان ها وجود دارند حتی اگر بخشی از زبان نباشند. این لزوما نباید یک نقطه ضعف باشد، زیرا انگلیسیسم به طور گسترده در بسیاری از زبان ها گسترش یافته است. من برای هر زبان سه آمار ایجاد کردم: ویکیپدیا حاوی نامهای مناسب زیادی است (یعنی نام گروهها) که اغلب حاوی یک «the» یا «and» هستند. به همین دلیل است که آن کلمات در بسیاری از زبان ها وجود دارند حتی اگر بخشی از زبان نباشند. این لزوما نباید یک نقطه ضعف باشد، زیرا انگلیسیسم به طور گسترده در بسیاری از زبان ها گسترش یافته است. من برای هر زبان سه آمار ایجاد کردم:
- مجموعه کاراکتر
- برخی از زبان ها دارای یک مجموعه کاراکتر بسیار خاص هستند (مانند چینی، ژاپنی، و روسی). برای دیگران، برخی از شخصیت ها اشاره خوبی به زبان های مورد نظر می دهند (به عنوان مثال، Umlauts آلمان).
-
N-Grams
- پس از تبدیل متن به کلمات (در صورت لزوم)، تعداد دفعات 1، 2 و 3 گرم شمارش شد. برخی از n-gram ها بسیار خاص زبان هستند (به عنوان مثال، "TH" در انگلیسی).
-
فهرست واژه
- آخرین منبع ابهامزدایی، کلماتی هستند که واقعاً استفاده میشوند. برخی از زبانها (مانند پرتغالی و اسپانیایی) در نویسههای استفاده شده و همچنین بروز n-gramهای خاص تقریباً یکسان هستند. با این حال، کلمات مختلف در فرکانس های مختلف استفاده می شود.
به مجموعه آماری مدل می گویند. من زیرمجموعه هایی از مدل "همه" ایجاد کرده ام که بهترین نیازهای من را برآورده می کند (جدول زیر را ببینید). مدل "متداول" شامل 10 زبان پرمکلم در جهان است. "کوچک" و "پیش فرض" بر اساس سناریوهای استفاده من است. اگر اهل بخش دیگری از جهان هستید، ممکن است ترجیحات شما متفاوت باشد. بنابراین لطفاً در انتخاب من از اینکه چه زبان هایی در کدام مدل وجود دارد، توهین نکنید.
تمام آمارها بر اساس وقوع آنها مرتب شده و رتبه بندی می شوند. در برنامه آزمایشی، همه مدل ها را می توان با جزئیات مطالعه کرد. طبقه بندی یک متن ناشناخته ساده است. متن نشانه گذاری می شود و سه جدول برای آمار تولید می شود. جدول نتیجه با تمام جداول مدل مقایسه می شود و فاصله محاسبه می شود. جدول مقایسه مدلی که کمترین فاصله را با متن مجهول دارد به احتمال زیاد زبان متن است.
| کد زبان | زبان | کیفیت | پیش فرض | مشترک | بزرگ | کوتاه |
|---|---|---|---|---|---|---|
| nl | Dutch | 13 | x | x | ||
| en | English | 13 | x | x | x | x |
| ca | Catalan | 13 | ||||
| fr | French | 13 | x | x | x | x |
| es | Spanish | 13 | x | x | x | x |
| no | Norwegian | 13 | x | x | ||
| da | Danish | 13 | x | x | ||
| it | Italian | 13 | x | x | ||
| sv | Swedish | 13 | x | x | ||
| de | German | 13 | x | x | x | x |
| pt | Portuguese | 13 | x | x | x | |
| ro | Romanian | 13 | ||||
| vi | Vietnamese | 13 | ||||
| tr | Turkish | 13 | x | |||
| fi | Finnish | 12 | x | |||
| hu | Hungarian | 12 | x | |||
| cs | Czech | 12 | x | |||
| pl | Polish | 12 | x | |||
| el | Greek | 12 | x | |||
| fa | Persian | 12 | ||||
| he | Hebrew | 12 | ||||
| sr | Serbian | 12 | ||||
| sl | Slovenian | 12 | ||||
| ar | Arabic | 12 | x | |||
| nn | Norwegian, Nynorsk (Norway) | 12 | ||||
| ru | Russian | 11 | x | x | ||
| et | Estonian | 11 | ||||
| ko | Korean | 10 | ||||
| hi | Hindi | 10 | x | |||
| is | Icelandic | 10 | ||||
| th | Thai | 9 | ||||
| bn | Bengali (Bangladesh) | 9 | x | |||
| ja | Japanese | 9 | x | |||
| zh | Chinese (Simplified) | 8 | x | |||
| se | Sami (Northern) (Sweden) | 5 |
برای شما کاربر عزیز پیشنهاد دانلود داده می شود