
دانلود دیتابیس مجموعه داده های فارسی استمینگ به منظور ارزیابی
شبکه های اجتماعی ما
دانلود دیتابیس مجموعه داده های فارسی استمینگ به منظور ارزیابی
مجموعه داده های فارسی استمینگ، شامل یک مجموعه از کلمات فارسی است که به صورت استمینگ شده یا با استفاده از روشهای تحلیل صرفی کاهش یافتهاند. این کلمات به صورت یک فایل متنی قابل دسترسی هستند و معمولا برای استفاده در پردازش زبان طبیعی و یا ساخت مدلهای یادگیری ماشین استفاده میشوند. مجموعه داده های فارسی استمینگ، به عنوان یکی از مجموعه داده های مهم در زمینه پردازش زبان فارسی شناخته شده است.
توضیحات در مورد استمینگ
استمینگ یکی از روشهای پردازش زبان طبیعی است که با استفاده از قواعد زبانی و الگوریتمهای مختلف، کلمات را به شکل پایه یا ریشه آنها تبدیل میکند. این روش معمولا در پردازش زبان طبیعی و تحلیل متن به کار میرود تا کلمات متفاوتی که در واقع به یک معنا یا ریشه مشترک مرتبط هستند، به یک شکل مشابه تبدیل شوند.
برای مثال، با استفاده از روش استمینگ، کلمههای "میروم"، "رفتهام" و "رفتیم" به کلمه "رفت" تبدیل میشوند. این کار برای پردازش متن و تحلیل آن بسیار مفید است زیرا با کاهش تعداد کلمات و تبدیل آنها به شکل پایه، میتوان به راحتی قواعد و الگوهای زبانی را شناسایی کرد و با این کار، تحلیل و پردازش متن را سریعتر و دقیقتر انجام داد.
استمینگ معمولا با استفاده از الگوریتمهای مختلفی انجام میشود. برخی از این الگوریتمها عبارتند از: الگوریتم پورتر، الگوریتم لما و الگوریتم نزدیکترین مسیر. این الگوریتمها با توجه به قواعد زبانی و الگوهای واژگانی، کلمات را به شکل پایه یا ریشه آنها تبدیل میکنند.
هیچ مجموعه داده استانداردی برای ارزیابی صحت الگوریتم های ریشه فارسی وجود ندارد. به منظور ایجاد یک مجموعه داده برای ارزیابی صحت پایهها، به مجموعهای از کلمات به همراه ساقه آنها نیاز داریم. این مجموعه داده ها به طور خودکار از دو مجموعه با ریشه دستی استخراج می شوند. اولین مجموعه داده شامل مجموعه ای از کلمات و ریشه آنها است که از مجموعه PerTreeBank [1] استخراج شده است. این مجموعه شامل 4689 کلمه متمایز است. علاوه بر این، برای انجام یک ارزیابی بهتر، یک مجموعه متن بزرگ را برای مجموعه داده دوم انتخاب کردیم. واژه ها و ریشه آنها از این مجموعه داده از مجموعه بانک درختی وابستگی فارسی [2] استخراج شده است. این شامل 26913 کلمه متمایز است. این دو مجموعه داده از نظر تنوع تگ های قسمت گفتار از کیفیت خوبی برخوردار هستند.
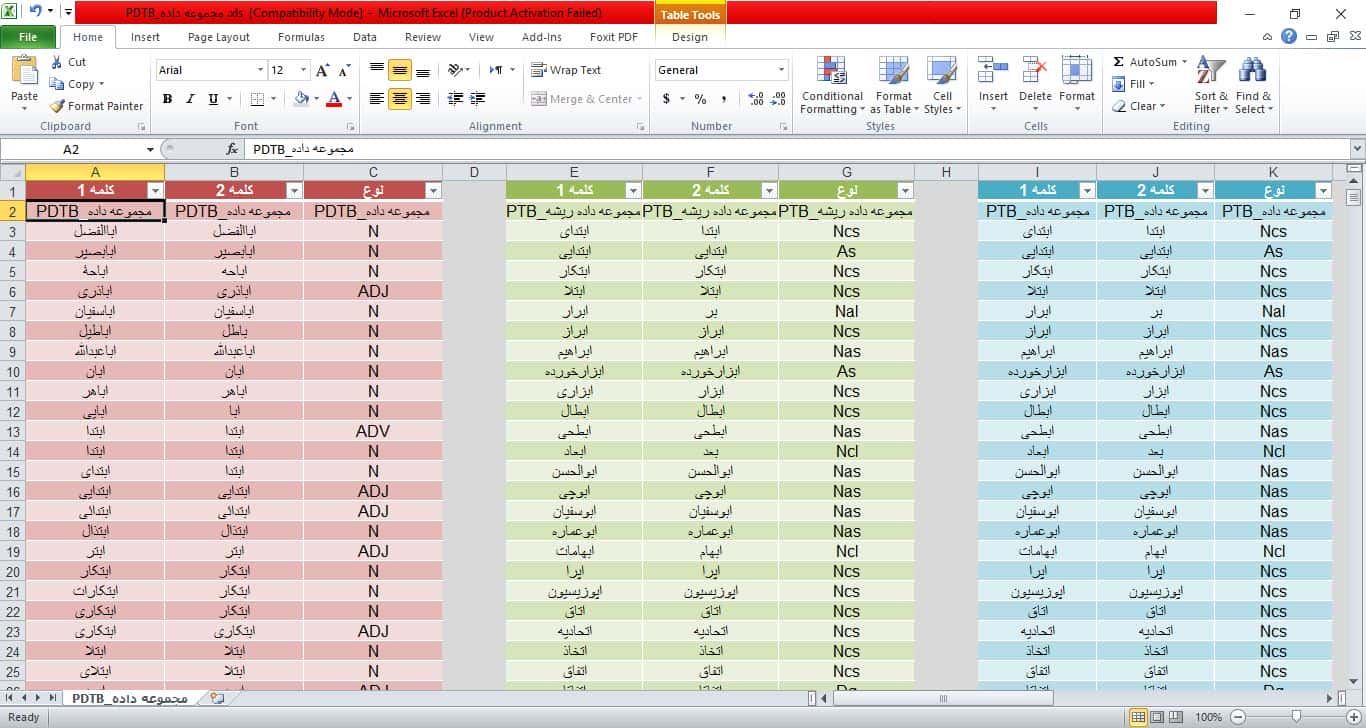
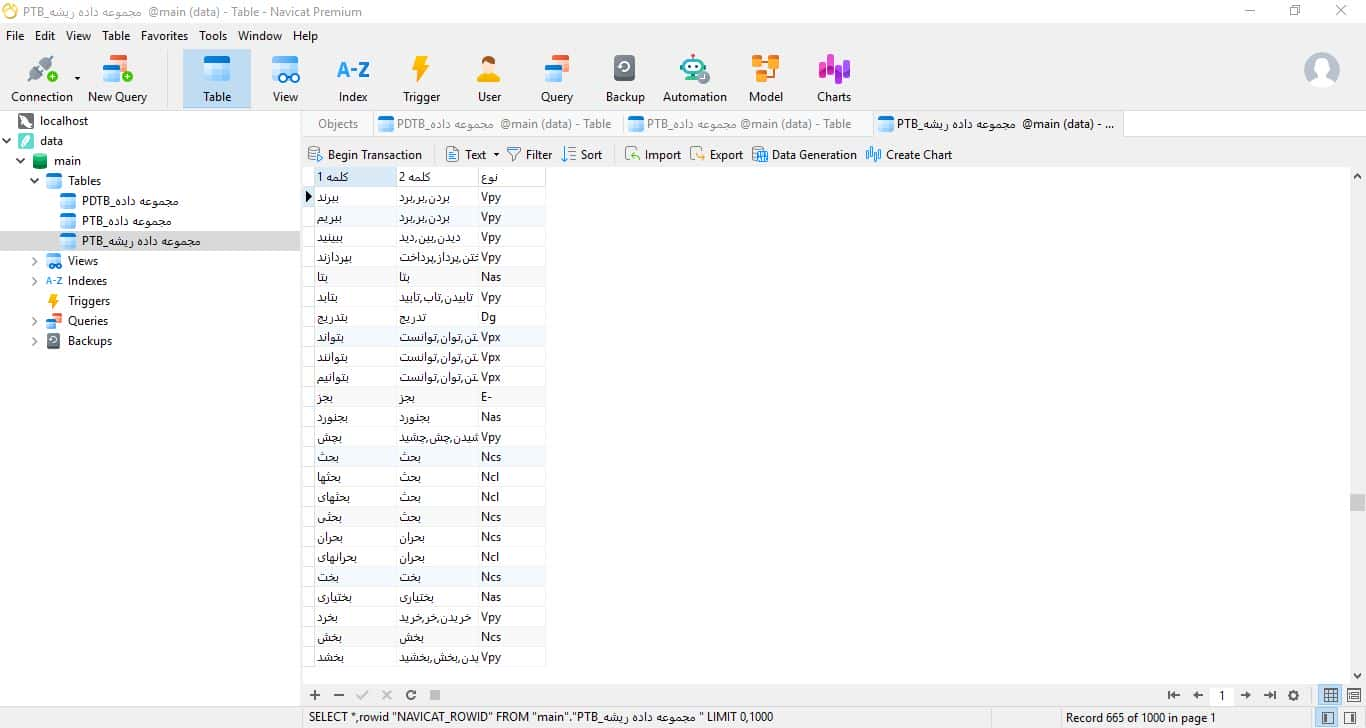
هر مجموعه داده ریشه ای از سه ستون تشکیل شده است. ستون اول کلمه عطف، دوم ریشه آن و سوم قسمت گفتار آن است. شما باید ریشه های خود را به ستون چهارم اضافه کنید. سپس می توانید از دستور زیر استفاده کنید.
نمونه تصاویر دیتابیس
برای شما کاربران عزیز پیشنهاد دانلود داده می شود.
ارسال نظر :
فایل های که ممکن است نیاز داشته باشید




نظرات کاربران :