لینک کوتاه : https://magicfile.ir/?p=4121
دانلود سورس کد الگوریتم تفاوت (Diff Algorithm) ژنریک و قابل استفاده مجدد در #C
امروز در این پست برای شما کاربران عزیز وبسایت فایل سحرآمیز یک سورس کد الگوریتم تفاوت (Diff Algorithm) ژنریک و قابل استفاده مجدد در #C را آماده دانلود قرار داده ایم.
سورس کد الگوریتم تفاوت (Diff Algorithm) ژنریک و قابل استفاده مجدد در #C میپردازد. اهداف اصلی این الگوریتم عبارتند از:
- حفظ مفاهیم اصلی ژنریک و قابل استفاده مجدد در الگوریتم اصلی ارایه شده توسط Aprenot.
- امکان کار با مجموعه های داده بزرگ به درستی.
- کاهش چشمگیر تعداد مقایسات لازم.
- کاهش چشمگیر نیاز به حافظه.
الگوریتم پیشنهادی در این سورس کد بر اساس الگوریتم ارایه شده توسط Aprenot است، اما برای رفع محدودیت های آن طراحی شده است.
در این الگوریتم، ابتدا طول بلندترین توالی مشترک (LMS) بین دو مجموعه داده پیدا می شود. سپس این LMS در یک لیست نتیجه ذخیره می شود. بعد، رکورسیو داده های بالا و پایین این LMS پردازش می شوند.
برای پیدا کردن LMS بدون نیاز به مقایسه همه موارد با همه موارد، از تکنیک های هوشمندانه استفاده می شود. این شامل تعیین محدوده های مشخص در هر مجموعه داده و استفاده از میان بری های ریاضی برای پرش از مقایسات غیر ضروری است.
نمونه تصویر در زمان اجرا
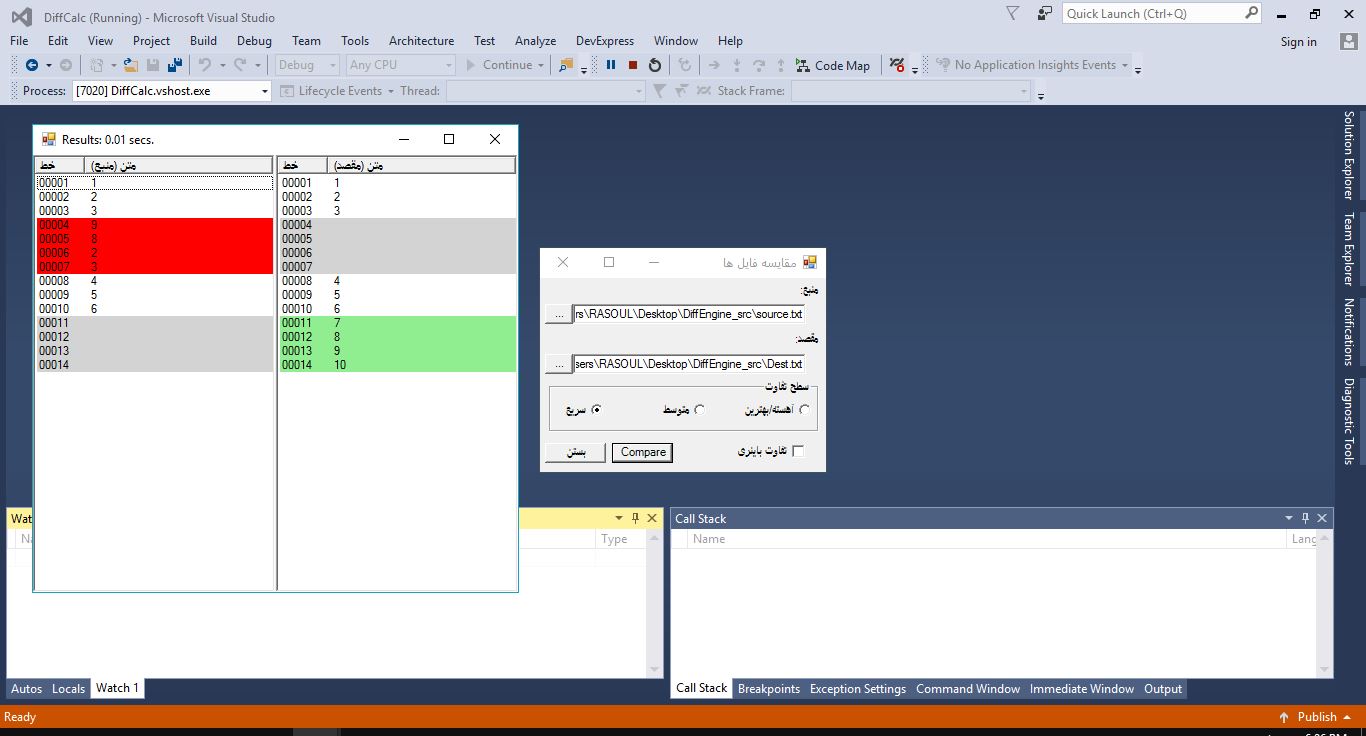
در مجموع، این الگوریتم با استفاده از رویکرد شبیه به QuickSort موفق می شود کارایی و حافظه مورد نیاز را بهبود بخشد، در عین حفظ قابلیت اتصال ژنریک و قابل استفاده مجدد که در الگوریتم اصلی وجود داشت.
جزئیات بیشتری در مورد این الگوریتم تفاوت (Diff Algorithm) به شما معرفی می کنم:
-
مفاهیم اصلی ژنریک و قابل استفاده مجدد:
- این الگوریتم مانند الگوریتم اصلی ارائه شده توسط Aprenot، یک الگوریتم ژنریک است که می تواند با هر نوع داده ای کار کند.
- این امکان را فراهم می کند که الگوریتم را به راحتی در پروژه های مختلف استفاده کرد.
-
کارایی با مجموعه های داده بزرگ:
- الگوریتم اصلی Aprenot با افزایش اندازه مجموعه های داده، دچار مشکل می شد.
- الگوریتم پیشنهادی در این مقاله، روش هایی را برای کار با مجموعه های داده بزرگ ارائه می دهد.
-
کاهش تعداد مقایسات:
- در الگوریتم اصلی، تمام موارد یک مجموعه با تمام موارد مجموعه دیگر مقایسه می شدند.
- الگوریتم پیشنهادی، با استفاده از تکنیک های هوشمندانه، تعداد مقایسات را به طور چشمگیری کاهش می دهد.
- این شامل تعیین محدوده های مشخص در هر مجموعه داده و استفاده از میان بری های ریاضی برای پرش از مقایسات غیر ضروری است.
-
کاهش نیاز به حافظه:
- الگوریتم اصلی نیاز به ذخیره یک جدول مقایسات داشت که با افزایش اندازه مجموعه ها، حافظه مورد نیاز افزایش می یافت.
- الگوریتم پیشنهادی، با استفاده از رویکردی شبیه به QuickSort، نیاز به حافظه را به طور چشمگیری کاهش می دهد.
در کل، این الگوریتم پیشرفته تر، توانسته است بر محدودیت های الگوریتم اصلی فائق آید و در عین حفظ قابلیت های ژنریک و قابل استفاده مجدد، کارایی و حافظه مورد نیاز را بهبود ببخشد.
برای شما کاربران عزیز پیشنهاد دانلود داده می شود.