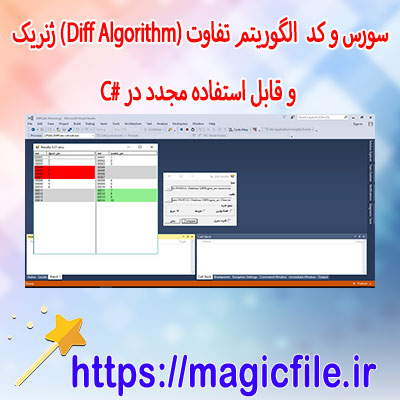
تفاوت الگوریتم (Diff Algorithm) ژنریک
الگوریتم تفاوت یا Diff Algorithm، ابزاری کارآمد برای شناسایی و مقایسه اختلافات بین دو مجموعه داده یا نسخههای مختلف یک فایل است. این الگوریتم به ویژه در زمینههای برنامهنویسی و مدیریت نسخه نرمافزار کاربرد دارد. در اینجا به توضیح جامعتری درباره این الگوریتم و انواع آن خواهیم پرداخت.
عملکرد و اصول اولیه
الگوریتمهای تفاوت بر اساس مقایسه خط به خط یا کلمه به کلمه عمل میکنند. به عبارت دیگر، آنها به دنبال شناسایی تغییرات، حذفها و اضافهها هستند. این فرآیند شامل مراحل زیر است:
- تحلیل ورودیها: ابتدا دو نسخه از دادهها یا فایلها تحلیل میشوند.
- مقایسه و شناسایی: الگوریتم شروع به مقایسه بخشهای مختلف میکند تا تغییرات را شناسایی کند.
- تولید خروجی: در نهایت، گزارشی از تفاوتها به صورت کاربرپسند تولید میشود.
انواع الگوریتمهای تفاوت
انواع مختلفی از الگوریتمهای تفاوت وجود دارد، از جمله:
- الگوریتمهای خطی: این نوع الگوریتمها به گونهای طراحی شدهاند که در زمان خطی عمل کنند. آنها معمولاً برای فایلهای بزرگ مناسب هستند.
- الگوریتمهای پیچیدهتر: این الگوریتمها ممکن است زمان بیشتری برای اجرا نیاز داشته باشند اما دقت بالاتری در شناسایی تفاوتها دارند.
کاربردها
این الگوریتمها در بسیاری از زمینهها کاربرد دارند، از جمله:
- نسخهبندی نرمافزار: برای شناسایی تغییرات در کدهای منبع.
- مقایسه متن: برای بررسی اختلافات در مقالات یا مستندات.
- مدیریت پایگاه داده: برای شناسایی تغییرات در دادهها.
نتیجهگیری
به طور کلی، الگوریتمهای تفاوت ابزارهای ضروری در دنیای مدرن فناوری اطلاعات هستند. آنها به کاربران کمک میکنند که به راحتی تغییرات را شناسایی کنند و در نتیجه، فرایندهای توسعه و مدیریت دادهها را تسهیل میسازند. در نهایت، انتخاب نوع مناسب الگوریتم بستگی به نیازهای خاص و حجم دادهها دارد.
کد الگوریتم تفاوت (Diff Algorithm): توضیح کامل و جامع
در اینجا قصد داریم به طور دقیق و جامع دربارهی الگوریتم تفاوت، که به زبان انگلیسی "Diff Algorithm" نامیده میشود، صحبت کنیم. این الگوریتم، یکی از مهمترین ابزارهای مقایسهی متنها، فایلها، یا دادهها است که در بسیاری از حوزهها، از جمله برنامهنویسی، مدیریت نسخه، و ویرایش متن، کاربرد فراوان دارد.
مبانی و هدف الگوریتم تفاوت
در اصل، وظیفهی این الگوریتم، مقایسهی دو مجموعه داده است؛ بهطور خاص، دو متن یا فایل، و پیدا کردن تفاوتهای موجود در آنها. هدف این است که مشخص شود چه بخشهایی در یک نسخه تغییر یافته، حذف شده یا اضافه شده اند. در نتیجه، خروجی این الگوریتم، معمولا شامل لیستی از تغییرات است — مثلا، خطوط اضافه شده، حذف شده، یا تغییر یافته.
روشهای اصلی و تکنیکهای مورد استفاده
در پیادهسازی این الگوریتم، چندین روش مختلف استفاده میشود. یکی از معروفترین تکنیکها، «الگوریتم لینی-ولش» (Longest Common Subsequence یا LCS) است، که بر پایهی یافتن طولانیترین زیررشته مشترک بین دو متن است. این روش، به خوبی میتواند تفاوتهای اصلی را نشان دهد، اما در عین حال، ممکن است در مواردی کند باشد، مخصوصا در فایلهای بزرگ.
علاوه بر آن، الگوریتمهای دیگر مانند «الگوریتم ویدن» (Wagner-Fischer) برای محاسبهی کمینهی هزینهی تبدیل یک رشته به رشته دیگر، و الگوریتم «مدلهای مبتنی بر ناشان» به نام «Diff Match Patch» که در زبانهای مختلف، مخصوصا جاوااسکریپت و پایتون، محبوب است، وجود دارند. این روشها، هر کدام، مزایا و معایب خاص خودشان را دارند، اما هدف مشترکشان، ارائهی بهترین راهکار برای مقایسه و نمایش تفاوتها است.
پیچیدگی و کارایی
یکی از مهمترین چالشهای الگوریتم تفاوت، مدیریت پیچیدگی زمانی و حافظه است. به طور معمول، الگوریتمهای پایه مثل LCS، در حالت کلی، زمان و حافظهی قابل توجهی مصرف میکنند. برای حل این مشکل، نسخههای بهبود یافته، مانند الگوریتمهای مبتنی بر برنامهریزی پویا یا الگوریتمهای تقریبی، توسعه یافتهاند تا بتوانند در زمانهای کوتاهتر و با مصرف حافظهی کمتر، نتایج قابل قبولی ارائه دهند.
کاربردهای عملی و نمونههای واقعی
در دنیای واقعی، این الگوریتم در موارد متعددی کاربرد دارد. مثلا، در سیستمهای کنترل نسخه، مانند گیتها (Git)، تفاوتها نشان داده میشوند تا تغییرات در کدهای برنامه مشخص شوند. در ویرایشگرهای متن، نشاندادن تفاوتها، کاربر را در اصلاح و اصلاح مجدد کمک میکند. حتی در مقایسهی فایلهای داده، برای بررسی تفاوتها و اصلاحات، این الگوریتم نقش حیاتی ایفا میکند.
نتیجهگیری و جمعبندی
در نهایت، الگوریتم تفاوت، ابزاری قدرتمند است که با ترکیب تکنیکهای مختلف، توانسته است به یکی از مهمترین ابزارهای مقایسه و مدیریت نسخه تبدیل شود. هرچند، بسته به نوع کاربرد، نیاز است که نوع الگوریتم و روش پیادهسازی مناسب انتخاب شود، تا تعادل بهینه بین دقت و کارایی برقرار گردد. این الگوریتم، با داشتن قابلیتهای گسترده و تطبیقپذیری، همچنان در حال توسعه و بهبود است، و نقش اساسی در مدیریت دادهها و توسعه نرمافزار دارد.
اگر نیاز دارید، میتوانم نمونه کدهای عملی و پیادهسازیهای خاص از این الگوریتم را هم برایتان شرح دهم.




